Friday, December 01, 2006
Adaptive Disk Scheduling
Debido a que estas MMDBMS, deben manejar constantemente cargas de trabajo (workloads), que varian con requerimientos muy variados, y debido a l gran tamano de los datos multimedia, implica que se debe usar almacenamiento secundario, y estos requerimientos tambien se imponene en el subsistema de almacenamiento.
Ya que la tecnologia cuenta con procesadores de alto rendimiento, y accesos a internet mas rapidos y baratos, el manejo de discos se tiene que colocar adelante tambien, y ahora con las base de datos multimedia, los algoritmos de planificacion de discos tradicionales, no se dan abasto.
Una implementacion de un Adaptive Disk Scheluding Algorithm es APEX.
APEX es capaz de proveer un numero diferente de tipos de servicios, QoS, y al mismo tiempo alcanzar una alta utilizacion de disco. Esto es posible debido a 4 tecnicas: (1), manejo de colas dinamicas, que mantienen el overhead del Scheduling framework bajo, y los reservaciones de actualizaciones del ancho de banda de acuerdo con el MMDBMS; (2) un modelo "extended token bucket", que asegura una distribucion correcta del ancho de banda del disco;(3) un principio de construccion por lotes, que saegura un alto uso de los discos y (4) una propiedad de conservacion de trabajo, que redistribuye el ancho de banda sin usar sin perdida de eficiencia de disco.
Thursday, November 23, 2006
RAID 10
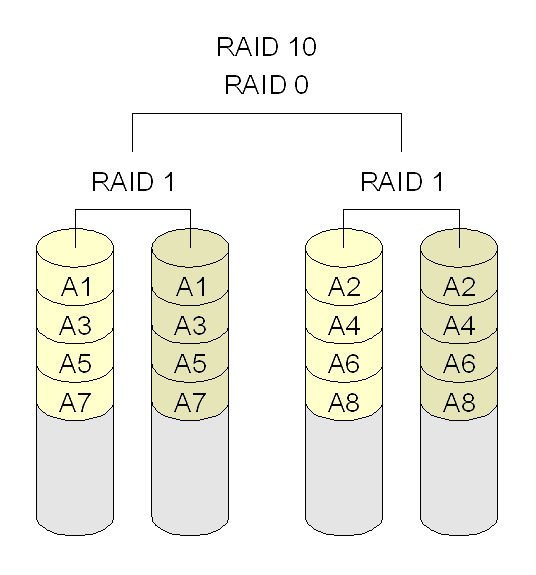
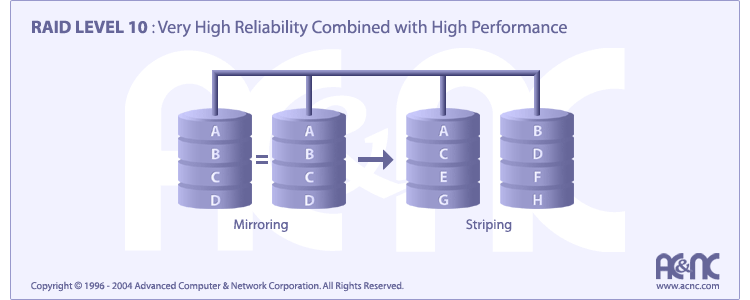
Un RAID 10, a veces llamado RAID 1+0, es parecido a un RAID 0+1 con la excepción de que los niveles RAID que lo forman se invierte: el RAID 10 es un división de espejos.
En cada RAID 1 pueden fallar todos los discos salvo uno sin que se pierdan datos. Sin embargo, si los discos que han fallado no se reemplazan, el restante pasa a ser un punto único de fallo para todo el conjunto. Si ese disco falla entonces, se perderán todos los datos del conjunto completo. Como en el caso del RAID 0+1, si un disco que ha fallado no se reemplaza, entonces un solo error de medio irrecuperable que ocurra en el disco espejado resultaría en pérdida de datos.
Debido a estos mayores riesgos del RAID 1+0, muchos entornos empresariales críticos están empezando a evaluar configuraciones RAID más tolerantes a fallos que añaden un mecanismo de paridad subyacente. Entre los más prometedores están los enfoques híbridos como el RAID 0+1+5 (espejo sobre paridad única) o RAID 0+1+6 (espejo sobre paridad dual).
El RAID 10 es a menudo la mejor elección para bases de datos de altas prestaciones, debido a que la ausencia de cálculos de paridad proporciona mayor velocidad de escritura.
Caracteristicas y Ventajas
RAID 10 esta implementado como un striped array cuyos segmentos con RAID 1 arrays.
RAID 10 tiene la misma tolerancia de fallo que el RAID nivel 1
RAID 10 tiene el mismo overhead para tolerancia a fallo como en mirroring solo.
Se obtienen alto rendimiento de I/O al tener segmentos RAID 1 striped.
Bajo ciertas circunstancias, el arreglo RAID 10 puede aguantar multiples y simultaneas fallas de discos.
Es una excelente solucion para los sitios de internet, porque sino tuvieran que tener RAID 1 y necesitarian un "boost" , de rendimiento adicional.
Desventajas
Muy Caro
Alto Overhead
Todos los discos se deben moverse en paralelo, para un mejor desenpeno para un mejor rendimiento correcto para sostener el track lowering
Es muy poca la rentabilidad y a un alto costo inherente.
Friday, November 17, 2006
Diferencia entre Codigo Objeto y Enlazado
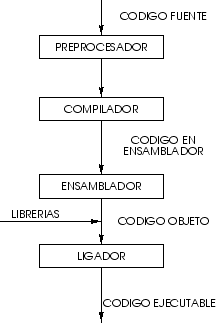
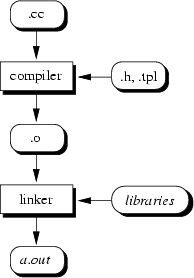
Cuando el programador da el comando de compilar, el compilador traduce el programa en codigo de lenguaje maquina(tambien conocido como codigo objeto) . En los sistemas C++, por ejemplo, antes de iniciar la fase de traduccion del compilador se ejecuta automaticamente un programa preprocesador. El preprocesador de c++ obedece ciertos comandos especiales, llamadas directivas de preprocesador, que indican que deben efectuarse ciertas manipulaciones al programa antes de compilarlo.
Estas manipulaciones por lo general consisten en incluir otros archivos de texto en el archivo a compilar y en efectuar el reemplazo de cierto texto. El compilador llama al preprocesador antes de convertir el programa a lenguaje de maquina.
Ligador o Enlazador:
La siguiente fase se llama enlace. Los programas por lo general contienen referencias a funciones definidas en otro lado, como en las bibliotecas estandar o en las bibliotecas privadas de los programadores que trabajan en un proyecto en particular. El codigo objeto que el compilador genera suele contener "agujeros" debido a estas partes faltantes. El editor de enlaces vincula el codigo objeto con el codigo de las funciones faltantes, generando una imagen ejecutable(sin partes faltantes).
Thursday, November 16, 2006
Laboratorio #1: Modificando Minix
Para empezar, este laborotario consta de tres partes:
1.- Familiarizarse con el archivo config.h
2.- modificar tty.c agregando un baner de nuestra preferencia
3.- compilar y re-compilar codigo fuente del kernel.
4.- Agregar en el archivo keyboard.c la opcion de F6 y que aparezca la lista de procesos mediante llamadas al sistema.
1.- Familiarizarse con el archivo config.h
En esta primera parte, con el comando vi, pude abrir el archivo config.h en /usr/include/minix.config.h, en cual contiene dos partes, una modificable por el usuario y otra que se modifica a partir de los parametros puestos por el usuario.
De las cosas que puedo mencionar, esta el hardware, que por defecto viene, con IBM_PC, el cual funciona para maquinas 8088, 8086, y derivados.
Pero si se tiene otro tipo de hardware se puede correr tambien, nada mas con #define
Tambien me fije que se puede modifica el largo de una palabra que por default esta de 4 bytes, el tamano de un entero, configuracion del kernel, caches, swapping, device drivers, sistema de archivos cache de segundo nivel, etc.
2.- Modificar tty.c agregando un banner de nuestra preferencia
Luego de navegar por el archivo config.h, pasamos al directorio /urs/src/kernel donde se encuentra los archivos de configuracion del kernel, codigo fuente.
el tty.c contiene codigo de minix, drivers del terminal, tambien la cosola de IBM y las terminales ASCII, maneja nada mas la parte independiente del equipo, de la tty.
Este archivo consta de dos entradas tty_task() y tty_wakeup(), el que nos interesa es el tty_task ya que tiene que ver con entradas de dispositivos como el teclado.
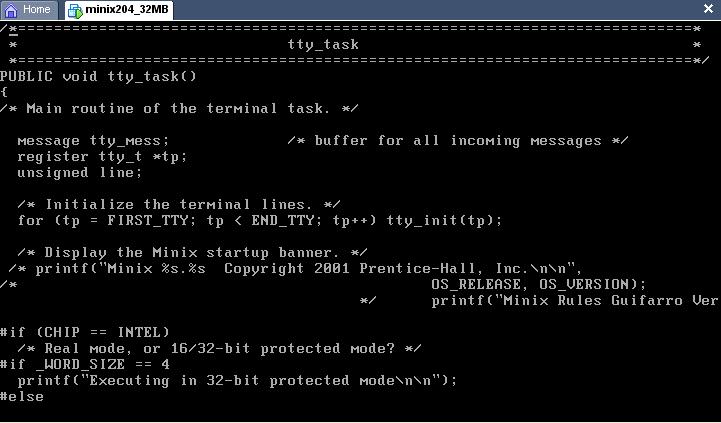
Despues de hacer el cambio en el kernel, procedi a compilarlo, ahora, como el kernel no ha sido compilado nunca y esta es la primera ves, no se puede hacer un backup de 2.0.4ro, ya que esta imagen la genera una ves que la compila, que fue lo que sucecio a continuacion:
en /usr/src/kernel le di make install, despues en /usr/src/tools, le di maje hdboot, y creo todos los archivos binarios que necesita, inclusive compilo el tty, y me lanzo un warning, de algo que me faltaba en el comentario.
Despues de reboot, el banner me quedo de la siguiente manera:
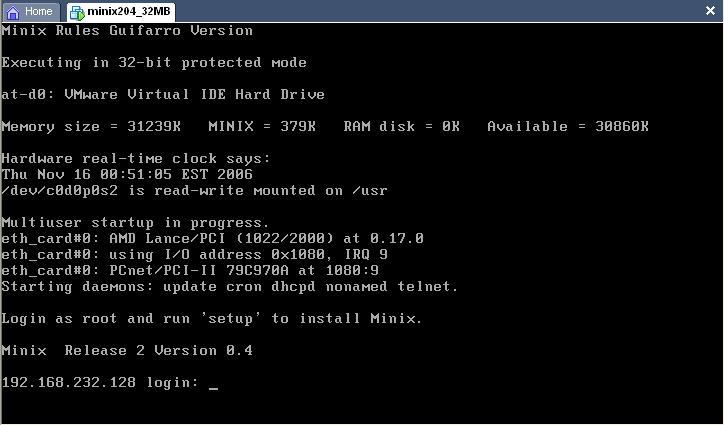 Donde esta el banner: "Minix Rules Guifarro Version"
Donde esta el banner: "Minix Rules Guifarro Version"Una ves que lo compilo la primera ves creo el archivo en el directorio /minix 2.0.4.4r1, el cual era la imagen r1.
Claro esta que en este proceso, encontre de mucha utilidad, esto de las imagenes del kernel, ya que cometi varios errores, en la modificacion del tty.c, y del keyboard, que explicare a continuacion, entonces nada mas habia que hacer el halt, y image=/minix/2.0.4.bak, y finalmente boot.
4.- Agregar en el archivo keyboard.c la opcion de F6 y que aparezca la lista de procesos mediante llamadas al sistema.
el archivo keyboard.c tiene la siguiente estructura con ciertos hot keys del 1 al 5. como se puede ver en la siguiente figura:
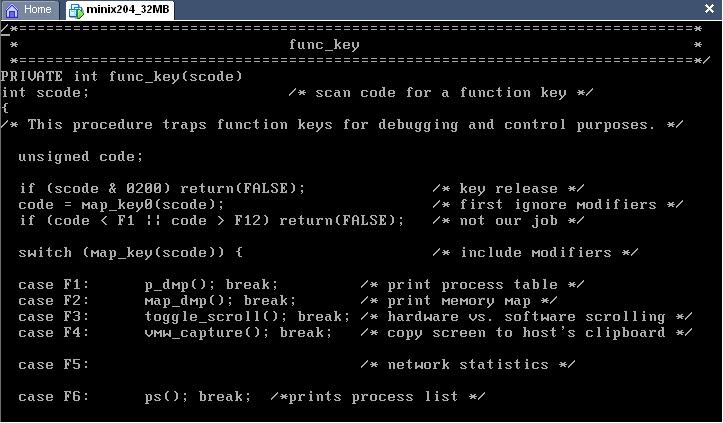 Entonces donde dice, F6 agregue la linea ps(); y brek;, pero no me funciono a la hora de compilar, ya que no reconoce esta funcion, ps, es para listar la lista de procesos, entonces, enves de usar utilice la funcion p_dmp(), la cual me la tabla de procesos, ya sea de usuario o del sistema, esta funcion la encontre en la documentacion de internet.
Entonces donde dice, F6 agregue la linea ps(); y brek;, pero no me funciono a la hora de compilar, ya que no reconoce esta funcion, ps, es para listar la lista de procesos, entonces, enves de usar utilice la funcion p_dmp(), la cual me la tabla de procesos, ya sea de usuario o del sistema, esta funcion la encontre en la documentacion de internet.y cada ves que se presiona esa secuencia sale lo siguiente:
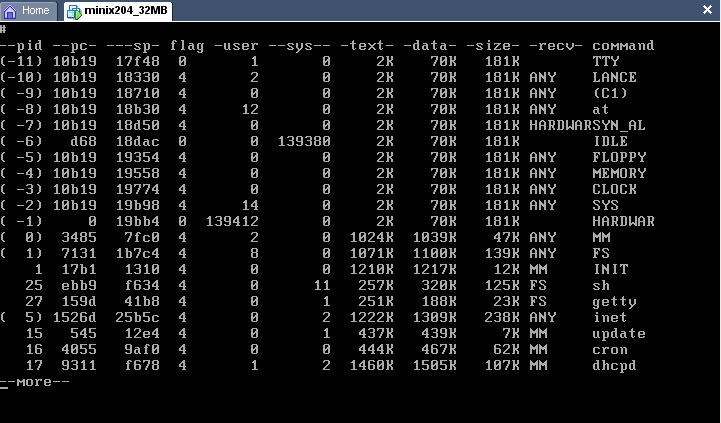 la cual desplega, el pid, process control block, usuario, sistema, etc
la cual desplega, el pid, process control block, usuario, sistema, etc5.- Conclusiones
Despues de haber completado esta laboratorio entontre ciertas cosas interesantes sobre minix, y de los sistemas operativos, como sre el lenguaje, librerias, compilacion, cosas que en sistemas como windows, nada mas se asumen, y de paso se puede modificar al gusto de cada quien, cosa que me gusto mucho mas. la verdad que la parte mas dificil fue lo de las llamadas al sistema, cosa que como no habia llevado minix antes, me costo bastante, pero espero haber salido.
Sunday, October 29, 2006
Simulador de Memoria Paginada
Primero para implementar los algoritmos use las sugerencias que salen en el libro de Tanenbaum,.
FIFO
Para este Algoritmo uso un arreglo para guardar el orden en que las paginas fueron ingresadas, y una cola para irlas reemplazando.
Second Chance
Es una pequeña modificación al algoritmo FIFO, que funciona bastante mejor que aquel. En este caso cuando una página debe ser sacada se toma la primera en la cola, y en vez de sacarla, consulta el valor de un bit de referencia. En caso de estar fijado (en 1) se cambia el bit a 0 y se lo coloca al final de la cola. De esta forma, se le da una segunda oportunidad. Si el bit se encuentra sin fijar, la página se saca de memoria.
NRU (Not Recently Used)
Este algoritmo es el analogo de LFU, ya que en los libros asi se le llama. Funciona de la siguiente manera: cuando una página es referenciada, fija el bit de referencia para esa página. Similarmente, cuando una página es modificada, fija su bit de modificación. Se utilizan las siguientes categorias con respecto al reemplazo.
- Categoría 0: no referenciada, no modificada
- Categoría 1: no referenciada, modificada
- Categoría 2: referenciada, no modificada
- Categoría 3: referenciada, modificada
Las mejores páginas para cambiar son las que se encuentran en la categoría 0, mientras que las peores son las de la categoría 3. Dentro de las páginas en categoría 0, se elige una página al azar para ser intercambiada.
Este algoritmo difiere del de 'No usada recientemente' en el hecho de que aquel sólo se fija en el intervalo de tiempo desde que se pusieron en 0 los bits de referencia de las páginas, mientras que el algoritmo de 'Menos usada recientemente' intenta proveer un comportamiento casi óptimo mediante la observación de las páginas que menos fueron usadas recientemente. Este tipo de páginas, estadísticamente son las que tienen menor probabilidad de ser usadas nuevamente. Aunque este algoritmo provee un buen comportamiento en teoría, es caro de implementar, en cuanto a recursos consumidos. Hay varias implementaciones que intentan mantener bajo el costo y lograr un rendimiento considerable. Un método consiste en tener una lista enlazada y ordenada de todas las páginas en memoria. En el final de la lista está la página menos recientemente usada, y al principio la más recientemente usada. El costo alto de este método es porque cada vez que se referencia una página debe ser movida en la lista, algo que consume mucho tiempo. Otra forma, que requiere soporte de hardware, consiste en tener un contador que es incrementado en cada instrucción del CPU. Cada vez que una página es accedida, gana el número del contador en el momento en ese momento. Cuando una página debe ser retirada de memoria, simplemente hay que buscar cuál es la que tiene el menor número, que es la que fue usada hace más tiempo. En el presente no existen contadores tan grandes para permitir esto. Debido al alto costo del LRU, se proponen algoritmos similares, pero que permiten implementaciones menos costosas, como los que siguen.
Este algoritmo tiene como finalidad retirar la página que vaya a ser referenciada más tarde, por ejemplo si hay una página A que será usada dentro de 10000 instrucciones, y una página B que será usada dentro de 2800 instrucciones, se debería eliminar de la memoria la página A. Como se puede deducir, para esto el sistema operativo debería ver en cuánto tiempo será usada cada página en memoria y elegir la que está más distante. El problema de este método es que necesita conocimiento del futuro, por lo que es imposible su implementación. Es un algoritmo teórico. Se utiliza a los efectos comparativos con los algoritmos factibles de ser implementados.
En nuestro caso que conocemos el "futuro" que es las siguientes reservaciones de memoria, entonces ordene el arreglo, usando quicksort que tiene un tiempo O(nlogn), y asi se ordena el archivo de manera que queden las que se usaran con mas frecuencia primero.
Preguntas Finales
1) ¿Qué estrategia de reemplazo de páginas escogería usted y por qué? Debe considerar los resultados obtenidos y el esfuerzo que le llevó implementar cada estrategia. Discuta lo que sus resultados muestran acerca de los méritos relativos de FIFO, LRU, LFU, Second Chance (CLOCK) y OPT para cada una de las diferentes combinaciones de parámetros.?
La que utilizaria seria LRU ya que en las simulaciones fue el que menos cambios tiene que hacer y mantiene una buena aproximacion con respecto al Optimo.
2) ¿Qué aspectos de la administración de memoria encontró que fue más difícil implementar?
La parte mas dificil de implementar fue la memoria paginada, ya que los algoritmos con ese manejar de bits de referencia se me hicieron dificil de manejar, que algunas cosas las tuve que hacer de otra manera para poder salir con eso, la verdad es que es demasiado ambiguo ciertas cosas.
3) ¿Qué aspectos de la administración de la memoria encontró más fácil implementar?
El de memoria continua, ya que se me hizo muy familiar a un proyecto de estructuras de Datos.
4) ¿Qué cambiaría en su diseño actual?
La verdad que le cambiaria, la manera de manejar el archivo de memorias, para motivos de la simulacion, (memoria paginada), no utilizaria hexadecimales, me parece que para efectos demostrativos, generaria numeros aleatorios, me parece mas facil.
Monday, October 09, 2006
Inicio de la Clase
![]()